What Can We Learn From the AWS Outage?
Published on 23/10/2025
AWS (Amazon Web Services) is globally renowned and recognised for being one of the very best providers for on-demand cloud computing platforms and APIs. Often considered the most prominent name in the cloud space, AWS powers a vast array of global services, including major platforms like Snapchat, Roblox, Fortnite, and Zoom.
Whilst their colossal stature and highly impressive client roster presents them to be a truly formidable force, AWS faced a humbling incident on the 20th of October 2025. A global outage struck the platform, disrupting operations across a wide range of services and platforms. In total, 113 services were affected, revealing vulnerabilities in even the most trusted cloud infrastructure.
In this blog, we’ll delve into the lessons learned from the outage, examining our reliance on infrastructure, the inherent risks of the SaaS model, and practical strategies for preparing for the inevitability of future disruptions.
The AWS outage began at 3.10 a.m. ET and lasted for several hours with AWS confirming the resumption of normal operations at around 10.11 a.m.
So, what was the root cause of the issue?
It was reported that the root cause of the outage was a technical update to the DynamoDB API. As a result, the Domain Name System (DNS) was affected, leading to a DNS issue. Regarding DNS, many refer to it as operating like a map, and so it can be said that on the 20th of October, AWS lost its bearings.
This DNS issue essentially stopped applications from resolving the correct server addresses, preventing them from connecting to the necessary databases. This led to numerous services that rely on DynamoDB to face significant disruption and downtime.
The AWS outage exposed and highlighted multiple critical vulnerabilities in cloud infrastructure and underscored the need for resilient, multi-region architectures. It’s important that businesses learn from this incident and ensure to evaluate their cloud strategies to avoid single points of failure and ensure business continuity.
Here are some key lessons that can be taken from the major incident:
The outage revealed how firmly established AWS is as a platform that powers the internet. From social media and banking apps to gaming and communication platforms, the AWS outage caused disruption across a range of sectors, affecting over 3,500 companies in over 60 countries. The outage is a stark reminder that relying on a single cloud provider or region can create systemic vulnerabilities.
The outage presents the impact of failing to internally monitor subsystems. This highlights the importance of distributing critical services across multiple regions and avoiding what’s sometimes referred to as ‘architectural bottlenecks.’
Cloud-native systems offer immense power, but only if built with resiliency, availability, and fault tolerance in mind. The outage emphasised the essential need for robust risk mitigation strategies and automated recovery mechanisms.
AWS’s delayed support case creation and vague early communications frustrated countless users. In such scenarios, timely updates and accessible support channels are absolutely essential.
SES Secure’s Head of Escrow and Continuity, Mark Ryan, recently created an article in which he delves into the AWS outage and how organisations can learn from it and improve their operational resilience and business continuity strategies. Check it out here.
While the SaaS model is often praised for reducing operational burdens due to its provision of automatic updates, vendor-managed maintenance, and the lack of on-premises infrastructure, it’s a misconception that this eliminates the risk of vendor-related disruptions. In reality, several critical risks remain:
To combat the above risks, we support clients with the implementation of SaaS Escrow, also known as Cloud Escrow.
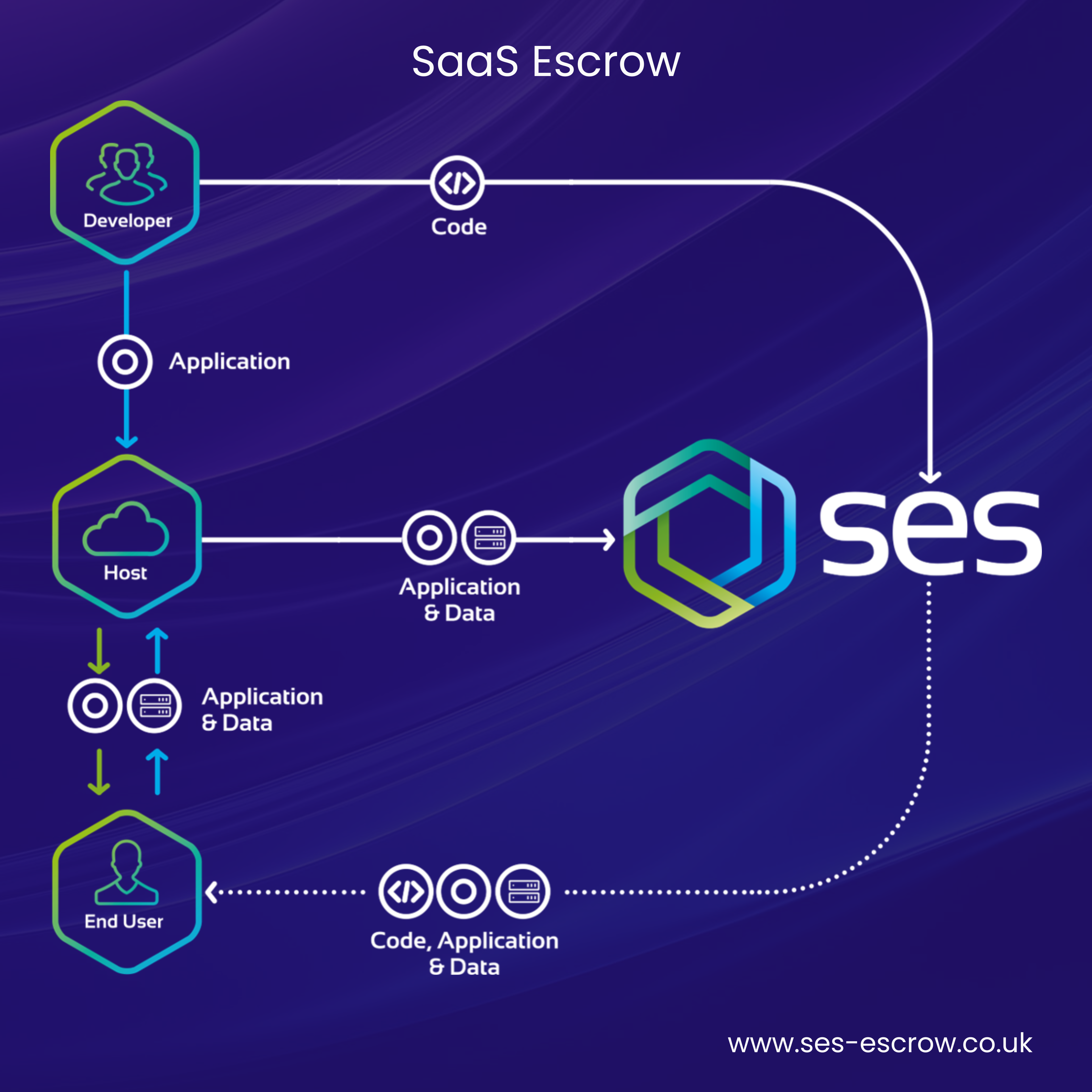
SaaS Escrow ensures that a critical cloud-hosted software application is readily accessible and operational in the event of vendor failure and/or disruption. Now, it’s important to recognise that SaaS Escrow isn’t rooted in mistrust…it’s a strategic measure designed to anticipate and prepare for any eventuality. By putting safeguards in place, developers, vendors, and clients alike can operate with greater confidence, knowing they’re protected against unforeseen disruptions and challenges.
Like traditional Software Escrow, SaaS Escrow involves a developer depositing source code and other materials with an Escrow provider. These materials are then tested to ensure that they are accurate, complete, and can be successfully redeployed. In line with any updates made to a critical application, new and updated deposits can also be made to the Escrow provider. These materials are securely stored and only released when a pre-determined Escrow release condition has been triggered, such as a vendor going out of business.
At SES, we’ve also launched our very own disaster recovery solution for SaaS systems. Introduced by SES Secure in 2021, SaaS Continuity stands out as a premier disaster recovery solution, uniquely designed to protect mission-critical applications with unmatched reliability.
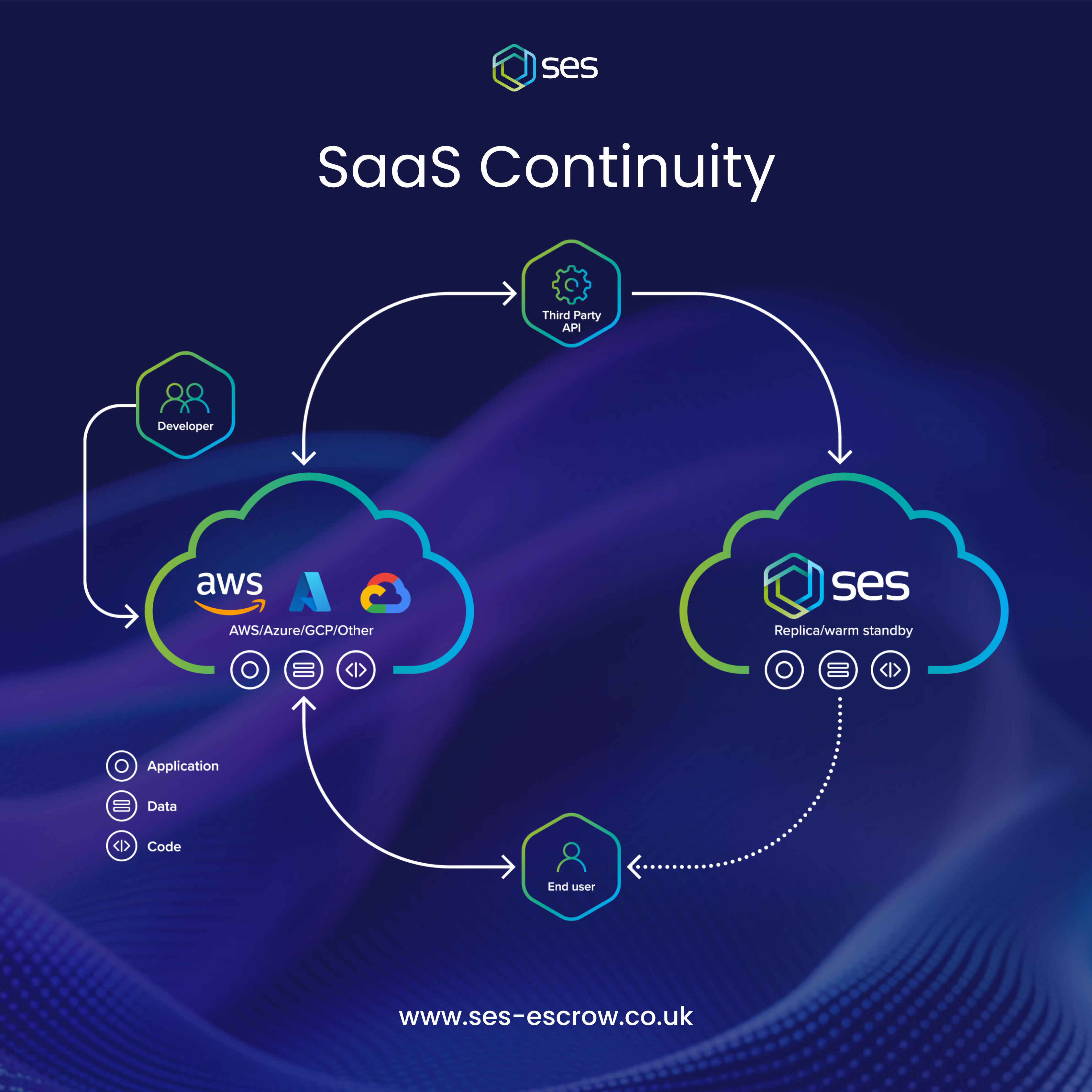
SaaS Continuity is designed with client convenience at its core. When activated, the SES Secure team swiftly assumes full responsibility for restoring the operational service on the client’s behalf. Once re-established, SaaS Continuity ensures a guaranteed window of uninterrupted service, giving clients peace of mind when they need it most.

To learn more about SaaS Continuity, check pout or blog – ‘SaaS Continuity – Disaster Recovery for Cloud-Hosted Applications’.
If you have any questions or would like to speak with a member of our team, please get in touch.